[대학원 강의]20240316 산업 AI 강의 정리
카테고리: Collage
전이학습 이란?
현재 AI는 전이학습으로 시작하여 전이학습으로 끝난다고 합니다. 그렇다면 전이학습이란 무엇일까요?
전이학습(Transfer learning)은 어떤 목적을 이루기 위해 학습된 모델을 다른 작업에 이용하는 것을 말합니다. 즉, 모델의 지식을 다른 문제에 이용하는 것으로 볼 수 있습니다.
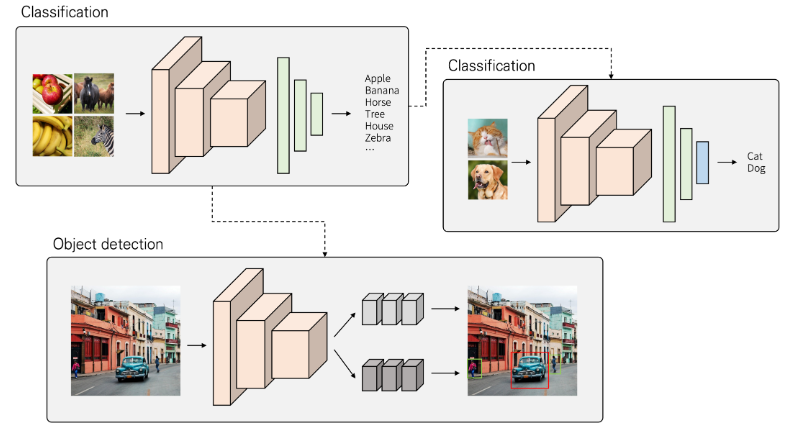
전이학습의 정의 대로 전이학습을 수행하기 위해서는 학습된 모델이 필요합니다. 그렇다면, 전이학습을 사용하는 이유는 무엇일까요?
전이학습을 사용하는 이유는 데이터의 양 때문 입니다. 예를 들어, 제가 프로그래밍에 대한 데이터를 차곡차곡 쌓았다고 쳐봅시다. 이 데이터는 신뢰성은 있을 지 몰라도, 전세계의 프로그래밍 데이터의 극히 일부밖에 되지 않습니다. 반대로, 구글 같은 대기업을 예로 들어 봅시다. 구글의 프로그래밍 데이터는 모든 데이터를 수집하기 때문에 신뢰성은 조금 떨어질 수 있어도, 그 양은 방대합니다. 어쩌면, 제가 모아둔 데이터도 종속되어 있을 수도 있습니다. 그래서, 결국 AI의 기본인 빅데이터를 기반으로 학습을 시키기 위하여 전이학습을 시킨다고 할 수 있습니다.
이것을 대기업들도 알기 때문에, 자신들이 모은 데이터를 바탕으로 모델링하여 시장에 제공을 하는 사업을 하고 있습니다. 대표적으로 OpenAI의 ChatGPT, Google의 Bard/Gemini, Microsoft의 Copilot 등등이 있습니다.
멀티모달 AI 이란?
멀티모달 AI는 연합학습(Federated Learning)의 한 종류 입니다. 멀티모달 AI는 여러가지 유형의 데이터 또는 정보를 함께 활용하여 인공 지능 시스템을 구축하는 접근 방식을 나타냅니다. 이러한 다양한 유형의 데이터는 주로 텍스트, 이미지, 음성, 비디오등이 있습니다.

멀티모달AI는 이러한 다양한 데이터를 조합하여 더 풍부하고 유용한 결과를 도출하고자 하는 목적으로 사용 됩니다.
모달리티(Modalities)는 서로 다른 감각이나 유형의 정보를 의미합니다. 예를들어, 텍스트 데이터는 언어적인 정보를 담고 있고, 이미지는 시각적 정보를 제공하며, 음성은 청각적 정보를 전달합니다. 멀티모달AI는 이러한 다양한 정보를 종합적으로 이해하고, 처리하여 보다 풍부하고 복합적인 작업을 수행할 수 있습니다.
정형/비정형/반정형 데이터란?
데이터는 AI 시대에 필수적 요소라고 할 수 있습니다.
그 데이터를 정형, 비정형, 반정형 과 같이 3종류로 나눌 수 있습니다.
정형 데이터
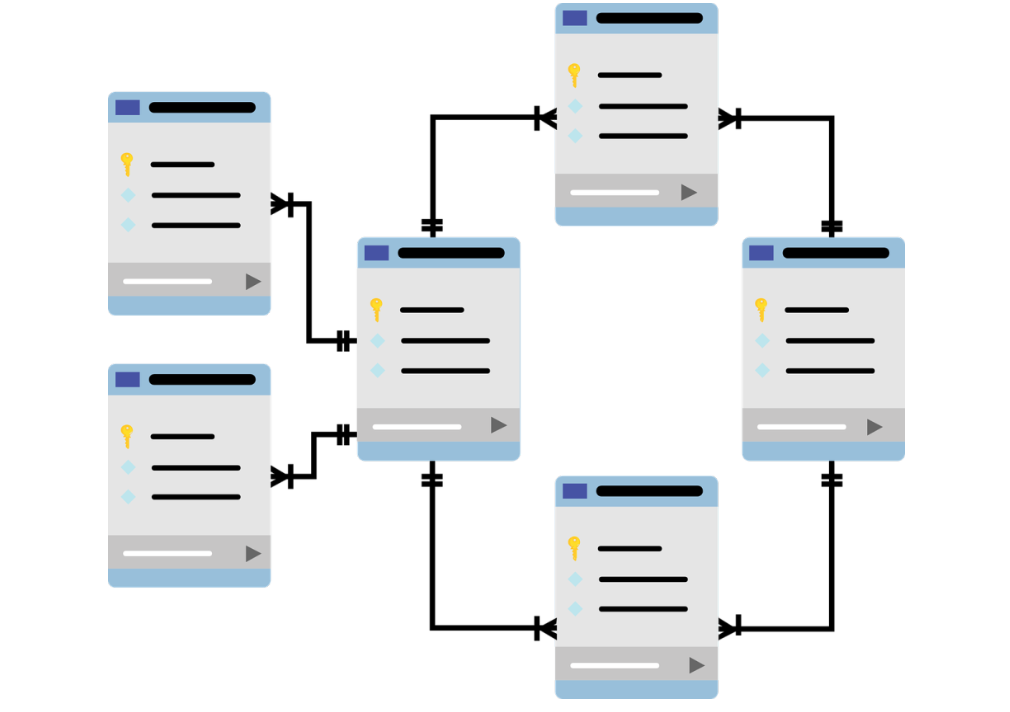
정형 데이터는 미리 정해 놓은 형식과 구조에 따라 저장되도록 구성하여 고정된 필드에 저장된 데이터 입니다.
간단하게 데이터베이스를 생각하면될 것 같습니다.
비정형 데이터
 비정형데이터는 정의된 구조가 없는 동영상파일, 오디오 파일, 사진, 보고서, 메일 등등 말 그대로 정형화 되지 않은 데이터 입니다. 즉, 연산이 불가능 합니다.
비정형데이터는 정의된 구조가 없는 동영상파일, 오디오 파일, 사진, 보고서, 메일 등등 말 그대로 정형화 되지 않은 데이터 입니다. 즉, 연산이 불가능 합니다.
그래서 연산을 하기 위해서 데이터 특징을 추출하여, 반정형 또는 정형 데이터로 변환하는전처리 과정이 필요 합니다.
해당 데이터는 서비스 제공자 이외에 커스터머에게 많이 사용 합니다.
반정형 데이터

반정형 데이터는 데이터의 구조 정보를 데이터와 함께 제공하는 파일 형식의 데이터로, 데이터의 형식과 구조가 변경될 수 있는 데이터 입니다.
프로그래밍을 하시는 분들은 자주 접하시는 xml, html, json 등등의 파일이 반정형 데이터 입니다.
교수님께서는 과제를 하실 때, 반정형 데이터를 제일 많이 사용하는 것 같다고 합니다.
그래서, 산업을 할 때는 정형 데이터와 반정형 데이터가 가장 중요하다고 합니다.
EDA 란?
EDA(Exploratory Data Analysis)는 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미합니다.
즉, 기획단계에서부터 이해가 잘 되고, 관계자들의 소통이 잘 된 프로젝트들은 일의 제작 및 수행과정이 그렇지 못한 프로젝트 보다, 훨씬 수월한 편입니다. 또한, 일을 진행하면서도 지속적으로 기획단계의 의도를 피드백하고 소통하는 팀은 프로젝트 결과의 질을 높게 향상시킬 수 있다고 생각합니다.
이번에 산업 AI 교수님은 아주 합리적으로, 도메인 분석 후, 일을 진행한다는 철학을 가지고 계신 듯 합니다. 저는 어떻게든 일찍 돈을 벌어야겠다는 급한 마음에 일단 뭐든 만들고 보자 라고 생각했는데, 이런점을 배워 앞으로는 기획단계를 더 철저히 가져야겠다는 생각이 들었습니다.
유전 알고리즘이란?
유전 알고리즘은 생물체가 환경에 적응하면서 진화해가는 모습을 모방하여 최적해를 찾아내는 최적화 방법 입니다. 유전 알고리즘은 이론적으로 전역 최적점을 찾을 수 있으며, 수학적으로 명확하게 정의되지 않은 문제에도 적용할 수 있기 때문에 다양한 응용 분야에서 매우 활발하게 이용되고 있습니다.
일반적으로 유전 알고리즘에 대해 알고리즘이라는 표현을 이용하지만, 유전 알고리즘은 특정한 문제를 풀기 위한 알고리즘이라기 보다는 최적화 문제를 풀기 위한 일반적인 방법론에 가깝습니다. 즉, 모든 문제에 적용 가능한 하나의 알고리즘이나 소스코드가 있는 것이 아니기 때문에 유전 알고리즘의 원리를 이해하고, 이를 자신이 원하는 문제에 적용할 수 있도록 설계하는 것이 중요합니다.
유전 알고리즘에서는 아래와 같은 개념을 바탕으로 알고리즘이 전개 됩니다.
-
염색체(Chromosome): 생물학적으로는 유전 물질을 담고 있는 하나의 집합을 의미하며, 유전 알고리즘에는 하나의 해(solution)을 표현 합니다.
-
유전자(Gene): 염색체를 구성하는 요소로써, 하나의 유전 정보를 나타냅니다. 어떠한 염색체가 A,B,C로 정의 된다면, 이 염색체에는 각각 A,B,C로 3개의 값을 갖는 유전자로 구성됩니다.
-
적합도(Fitness): 어떠한 염색체가 갖고 있는 고유값으로써 해당 문제에 대해 염색체가 표현하는 해가 얼마나 적합한지를 나타냅니다. 예를들어 어떠한 경로를 이동하는 비용을 최소화하기 위해 유전 알고리즘을 적용한다면, 염색체의 적합도는 비용의 역수가 될 것 입니다.
알고리즘의 구조
유전 알고리즘은 현재 시점에 존재하는 염색체들의 집합으로부터 적합도가 가장 좋은 염색체를 선택하고, solution space에서 선택된 염색체가 나타내는 방향으로 탐색을 반복하며 최적해를 찾아갑니다. 동작을 단계별로 나타내면 다음과 같습니다.
- 초기 염색체 집합 생성
- 초기 염색체들에 대한 적합도 계산
- 현재 염색체들로부터 자손들을 생성
- 생성된 자손들의 적합도 계산
- 종료 조건 판별
유전 알고리즘에 대한 예시를 모델링한 영상이 있습니다. 그네를 타는 영상인데, 처음에는 엉성하게 타다가, 세대를 거쳐가며 그네를 더 잘타는 개체가 나옵니다.
https://www.youtube.com/watch?v=Yr_nRnqeDp0
댓글 남기기