[AI/python] 훈련셋과 테스트셋 나누기(홀드아웃, k-겹 교차검증)
카테고리: AI
훈련셋과 테스트셋
딥러닝을 할 때, 가장 조심해야 하는 부분은 바로 과적합 입니다. 과적합이란 너무 과하게 학습하여, 데이터의 패턴이 아닌 노이즈까지 학습해버리는 문제를 말합니다. 이렇게 되면, 훈련 데이터셋에서는 아주 좋은 예측률을 보이지만, 새로운 데이터에 대해서는 성능이 크게 떨어지는 문제가 발생합니다. 즉, 모델이 데이터를 일반화하여 추론하는 능력보다 학습된 데이터에 대한 기억에 더 치우친 상태가 된것입니다.
과적합을 막기위해, 학습 조기중단, 데이터 양 늘리기, ` 가중치 규제 등등 많은 기법들이 있습니다. 이번 포스팅에서 다룰 기법은 기존 데이터를 유지하면서 과적합을 방지할 수 있는 훈련셋과 테스트셋 나누기`기법을 다룹니다.
훈련셋과 테스트셋 나누기는 100의 학습 데이터가 있다면 그것의 70% 정도를 학습할 데이터 셋으로, 30%를 학습된 모델을 테스트할 용도로 사용하게 됩니다. 이것이 기본적인 방식입니다.
여기서 훈련해야 할 데이터마다의 효과를 더 올리기 위해서 다양한 기법들이 존재하게 됩니다. Hold Out, K-겹 교차검증, Time Series Split(시계열 검증) 등등이 있습니다.
이번포스팅에서는 Hold Out. K-겹 교차검증에 대해서 다룹니다.
홀드아웃 방식
가장 단순한 방식입니다. 데이터를 훈련셋과 테스트셋으로 한번만 분리해서 평가하는 방식입니다.
해당 방식을 구현할 때, 사이킷 런의 테스트 스플릿 함수를 사용하게 됩니다.
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('../data/sonar3.csv', header = None)
X = df.iloc[:,0:60]
y= df.iloc[:,60]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle = True)
model = Sequential()
model.add(Dense(24, input_dim = 60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer = 'adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs = 200, batch_size=10)
score = model.evaluate(X_test, y_test)
print('test accuracy :', score[1])
위 코드를 보면, 데이터를 불러오는 부분은 동일합니다. 다만 달라지는 것은, 그 아래에 훈련셋과 테스트셋을 나누는 구간입니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle = True)
model.compile(loss='binary_crossentropy', optimizer = 'adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs = 200, batch_size=10)
이렇게하면, 사이킷런의 함수에 따라서 (X_train, X_test, y_train, y_test)가 70% 30%으로 나누어져 데이터가 담기게 됩니다.
그 후에, 딥러닝 계층을 만들어서 학습을 시킵니다.
model = Sequential()
model.add(Dense(24, input_dim = 60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
X_train, y_train 을 통해 학습된 결과를 X_test, y_test 를 통하여 얼마나 정확도가 있는지 테스트해봅니다.
테스트를 할때는 model.evaluate()함수를 사용하여 테스트를 하게 됩니다. 이 함수를 돌리면 아래와 같이 정확도가 나오게 됩니다. 이번 테스트에는 85%의 정확도를 가진 모델이 탄생한것을 볼 수 있습니다. 그리고 같은 데이터셋으로 훈련하고, 테스트하면 비슷한 정확도가 나올 수 있기 때문에, 훈련 데이터셋을 만들때 Shuffle = True옵션을 통해서 train_test_split함수가 호출될때 마다 순서가 뒤바뀌도록 설정합니다.

K-겹 교차검증
위의 Hold Out방식을 사용하면 학습과 예측이 잘 되는것처럼 보이지만, 한가지 치명적인 단점이 있습니다. 바로 데이터양이 가장 중요한 딥러닝에서 데이터의 30%나 테스트셋으로 사용한다는 점입니다. 그래서 나온 방법이 K-겹 교차검증 입니다.
K-겹 교차검증의 방식은 다음과 같습니다. 우선 100의 데이터가 있다라고 하면, 이것을 4등분 (나누고싶은 만큼 설정)합니다. 그리고 이 중 하나를 테스트셋으로 사용하게 됩니다. 3개의 학습셋과 1개의 테스트셋을 설정하고 나면, 테스트셋으로 사용했던 뭉치와 학습셋으로 사용했던 2개의 뭉치를 합쳐 다시 학습셋으로 사용합니다. 그리고 학습셋으로 사용했던 하나의 뭉치를 다시 테스트셋으로 사용하는 방식입니다. 그림으로 표현하면 다음과 같습니다.
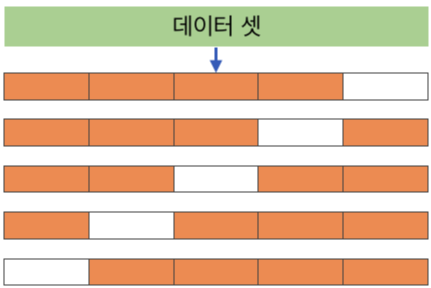 (주황색 부분이 학습셋, 흰색부분이 테스트셋 입니다.)
(주황색 부분이 학습셋, 흰색부분이 테스트셋 입니다.)
즉, k-겹 교차검증에서의 k는 학습을 시키는 사람이 정해야 하며, 이는 데이터의 크기나 종류에 따라 달라질 수 있습니다. 위 그림은 5겹 교차검증이라고 표현하게 됩니다. 이것을 코드로 나타내면 다음과 같습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
df = pd.read_csv('../data/sonar3.csv', header = None)
X = df.iloc[:, 0:60]
y = df.iloc[:,60]
k = 5
kfold = KFold(n_splits=k, shuffle = True)
acc_score = []
def model_fn():
model = Sequential()
model.add(Dense(units = 24, input_dim = 60, activation = 'relu'))
model.add(Dense(units = 10, activation = 'relu'))
model.add(Dense(units = 1, activation = 'sigmoid'))
return model
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1]
acc_score.append(accuracy)
avg_acc_score = sum(acc_score)/k
print("정확도: ",acc_score)
print("정확도 평균: ", avg_acc_score)
우선, 몇겹으로 수행할지에 대한 변수를 선언하게 됩니다. 그리고, 사이킷런의 KFold 함수를 호출하여 데이터셋을 쪼개도록 합니다.
k = 5
kfold = KFold(n_splits=k, shuffle = True)
그리고, 반복문을 돌리기 위해서, 모델을 만드는 과정을 함수화 합니다.
def model_fn():
model = Sequential()
model.add(Dense(units = 24, input_dim = 60, activation = 'relu'))
model.add(Dense(units = 10, activation = 'relu'))
model.add(Dense(units = 1, activation = 'sigmoid'))
return model
그다음, kfold 에 들어있는 뭉치들을 하나씩 바꿔가며 학습을 진행하는 반복문을 돌립니다. 지금은 5개로 나누었기 때문에, 학습셋, 테스트셋을 5번 갈아끼우며 학습을 진행하게 됩니다.
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1]
acc_score.append(accuracy)
마지막으로, 학습이 끝나고 정확도를 리스트에 담아, k로 나눠주면 정확도의 평군이 구해지게 됩니다.

결론
테스트을 위한 데이터를 늘리는것은 현실에서는 굉장히 힘듭니다. 그렇지만, 학습된 모델을 테스트하지 않는다면 그 모델은 실전에서 사용할 수 없는 모델이 될 수 있습니다. 그렇기에 학습해야하는 데이터의 종류를 잘 파악한 뒤 그에 맞는 테스트방법으로 모델을 테스트해 어느정도의 정확도가 있는지 테스트해보는것이 중요합니다.
댓글 남기기