[AI/python] 훈련셋과 검증셋 나누어 모델 업데이트 하기
카테고리: AI
지난 포스팅에서는 모델의 훈련셋과 테스트셋에 대해서 작성되었습니다. 이번 포스팅에서 다뤄볼 것은 훈련셋과 검증셋입니다. 테스트셋은 훈련이 끝난 모델을 모델 출시 직전 대입해보고, 정확도를 분석하는 용도로 사용했다면, 검증셋은 훈련중에 모델의 성능을 지속적으로 평가하고, 하이퍼파라미터 조정과 같은 모델 튜닝을 위해 사용됩니다. 전체코드는 아래와 같습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('../data/wine.csv', header=None)
X = df.iloc[:,0:12]
y = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
modelpath="./data/model/all/{epoch:02d}-{val_accuracy:.4f}.keras"
checkpointer = ModelCheckpoint(filepath=modelpath, verbose=1)
history=model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split=0.25, verbose=0, callbacks=[checkpointer])
score = model.evaluate(X_test, y_test)
print('Test accuracy: ',score[1])
여기서, 달라지는 부분은 모델을 저장하는 부분과, 모델을 fit하는 부분입니다.
우선, 모델을 fit 하는 부분을 먼저 봅니다.
history=model.fit(X_train, y_train, epochs=50, batch_size=500, validation_split=0.25, verbose=0, callbacks=[checkpointer])
여기서 새롭게 추가된 인자로는 validation_split 이라는 인자 입니다. 0.25로 설정하였으면, X_train, y_train 중에서 25%를 검증용 데이터로 자동 분리하겠다는 의미입니다. 그리고, checkpointer를 사용해서 모델을 저장하게 됩니다. 인자로 있는 callback 함수가 모델의 학습이 끝났을 때, checkpointer를 호출하여 모데을 저장하게 됩니다.
여기서, 검증셋의 역할은 epoch가 50일때, 50번째가 아닌 그 전에 유의미한 학습결과가 있다면, 그 때의 모델을 저장하도록 하게 해줍니다.
이제, 그래프로 표현하여 확인해봅시다.
y_vloss = hist_df['val_loss']
y_loss=hist_df['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, "o", c="red", markersize=2, label='Testset_loss')
plt.plot(x_len, y_loss, "o", c="blue", markersize=2, label='Trainset_loss')
plt.legend(loc='upper right')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
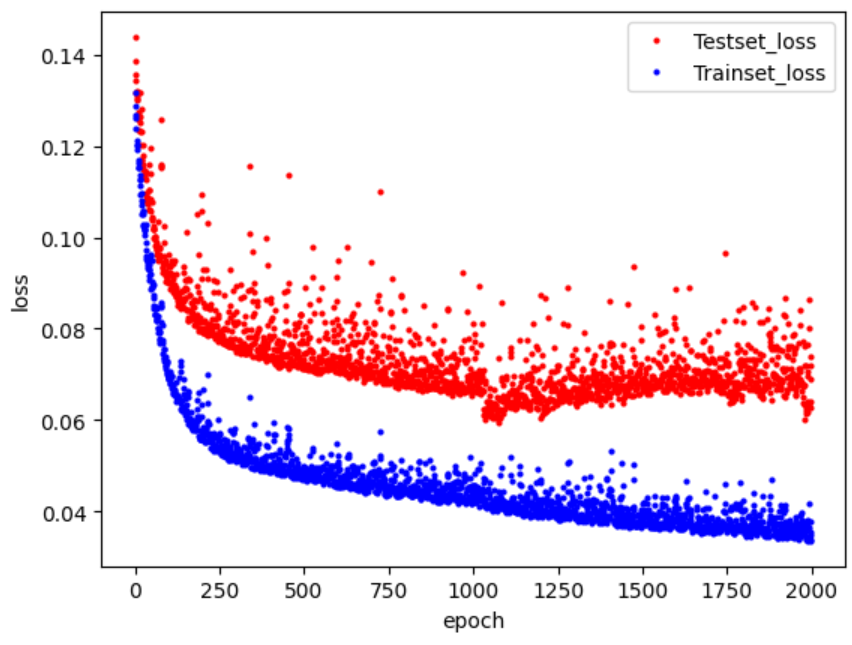
그래프에서 빨간색 부분은 학습한 모델을 검증셋에 적용해 얻은 오차이고, 파란색 부분은 학습셋에서 얻은 오차 입니다.
여기서 눈여겨 봐야할 점은 학습이 오래 진행될수록 검증셋의 오차(파란색)는 줄어들지만, 테스트셋의 오차(빨간색)은 다시 커진다는 점입니다. 이는 과도한 학습으로 과적합이 발생했기 때문입니다. 이러한 사실을 통해 알 수 있는 것은 검증셋의 오차가 커지기 직전까지만 학습한 모델이 최적의 횟수로 학습한 모델이라는 것입니다.
그렇다면, 검증셋의 오차가 커지기 전에, 학습을 자동을 ㅗ중단시키고, 그때의 모델을 저장하는 방법은 어떤것이 있을까요?
keras라이브러리에서는 EarlyStopping()함수를 제공하게 됩니다. 학습이 진행되어도 테스트셋 오차가 줄어들지 않으면 학습을 자동으로 멈추게 하는 함수입니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=20)
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=0, save_best_only=True)
history=model.fit(X_train, y_train, epochs=2000, batch_size=500, validation_split=0.25, verbose=1, callbacks=[early_stopping_callback,checkpointer])
검증셋의 오차를 val_loss 라고 지정합니다. 그리고 patience인자에 20이라는 값이 세팅되어 있습니다. 이 patience인자는 지정된 값이 몇 번 이상 향상되지 않으면 학습을 종료시킬지에 대한 옵션입니다. 지금은 20으로 설정했으므로, 검증셋의 오차가 20번이상 낮아지지 않을 경우 학습을 종료하라는 뜻이 됩니다.
다음은, ModelCheckpoint 함수에 save_best_only 라는 인자가 True로 추가된것을 볼 수 있습니다. 그리고 어차피 최적의 epoch에서 모델이 저장될것이기 때문에 epochs는 2000으로 늘려줍니다.
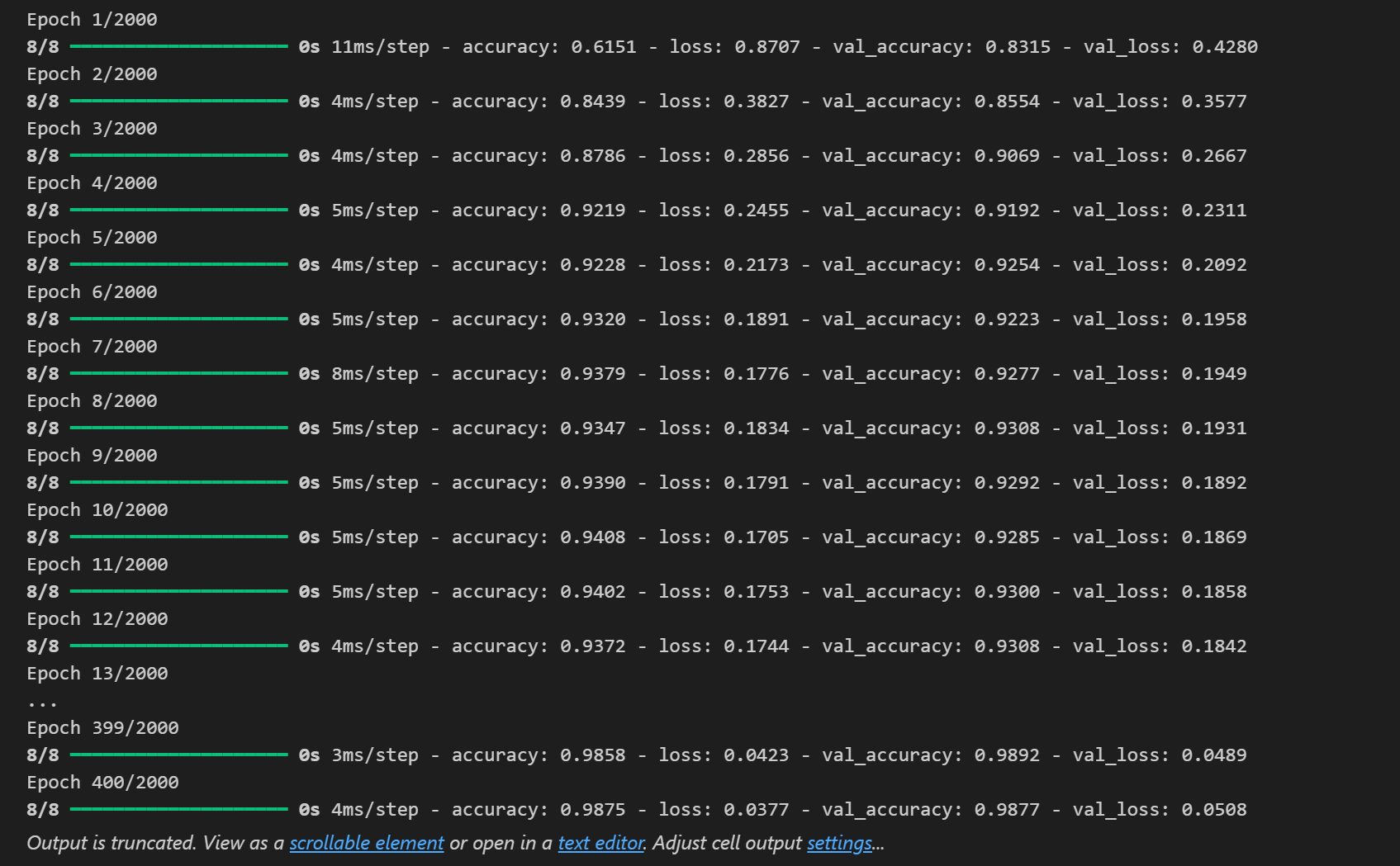
이렇게 세팅을 하고 모델을 돌리면 다음 결과에서 볼 수 있듯이, 400번째에서 학습이 멈추게 됩니다.
이렇게하여 과적합을 방지하면서 오차를 최소화할 수 있는 방법을 알아보았습니다.
댓글 남기기