[AI/python] 딥러닝 신경망 예제
카테고리: AI
다음은 환자 진찰 기록을 가지고 1년 후 이 환자가 생존했는지, 사망했는지의 데이터들을 통해 예측을 하는 딥러닝 모델을 구축하는 코드입니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
Data_set = np.loadtxt("../data/ThoraricSurgery3.csv", delimiter=",")
X = Data_set[:,0:16]
y = Data_set[:,16]
model = Sequential()
model.add(Dense(units = 30, input_dim=16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X, y, epochs=5, batch_size=16)
이 코드를 하나씩 분석해 보겠습니다.
우선, 딥러닝을 쉽게 할 수 있도록 Google 에서 만든 keras라이브러리와 python에서 숫자 계산을 쉽게 하게 해주는 numpy모듈을 임포트 합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
그리고, numpy 의 loadtxt함수를 통해 환자 데이터를 가져옵니다.
만약 100행 16열 짜리 데이터를 가져왔다고 가정합니다. 마지막 16열째 데이터는 1~15열째 데이터를 바탕으로 1년후에 생존했는지 사망했는지를 알려주는 결과와 같은 데이터 입니다.
인공지능에서는 1~15열까지의 데이터를 어트리뷰트, 결과에 해당되는 16열을 클래스라고 부릅니다. 우리는 1~15일치의 데이터를 입력하면 16열째 즉, 1년뒤에 이 환자가 생존하였는가? 를 예측하는 모델을 만드는것 입니다.
어트리뷰트는 보통 소문자y로 표기하고 클래스는 보통 대문자 X로 표기하게 됩니다.
Data_set = np.loadtxt("../data/ThoraricSurgery3.csv", delimiter=",")
X = Data_set[:,0:16]
y = Data_set[:,16]
이제, 학습할 데이터들을 변수에 담았으니, 학습을 위한 신경망을 구축하는 코드를 구성합니다.
model = Sequential()
model.add(Dense(units = 30, input_dim=16, activation='relu'))
model.add(Dense(units = 1, activation='sigmoid'))
model.summary()
Sequential()은 층을 순차적으로 하나씩 쌓을 수 있을 때 사용하는 함수입니다.
model.add(Dense(units = 30, input_dim=16, activation='relu'))
위 코드를 보면, add()함수를 통해 Sequential()에 하나씩 층을 쌓을 수 있습니다. 자주 쓰이는 인자로 units, input_dim, activation등이 있습니다.
units: units 는 결과를 도출할 출력노드 입니다.input_dim: input_dim 은 입력 데이터의 갯수 입니다.activation: activation 은 활성화 함수라고 합니다. 활성화 함수는 계산된 값을 어떻게 다음층으로 전달할것인가? 에 대한 부분입니다. 만약 활성화 함수가 y = x 인 선형 함수라면, 1의 값이 그대로 다음층에 1로 전달되게 됩니다.
지금 쌓은 모델은 어트리뷰트가 1~15열 까지 이므로, 입력이 16개라고 볼 수 있습니다. 그것들을 30개의 층에 넘기고, 원하는 결과가 16열 (생존했는지, 사망했는지 여부)이므로 1개의 출력을 원하는것을 알 수 있습니다. 따라서 마지막 출력층에는 units = 1 로 하나의 출력만 보겠다라는 의미입니다.
위 모델을 그림으로 그리면 다음과 같이 표현할 수 있습니다. (각 노드를 연결하는 선은 너무 많아서 생략하였습니다.)

마지막으로, 모델을 컴파일하고, 모델을 학습하는 코드입니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X, y, epochs=5, batch_size=16)
여기서, compile()함수에 loss와 optimizer 라는것이 있는데 이는 순서대로 손실함수, 오차가 가장 작은 가중치로 업데이트 하는 방법이라고 보면 됩니다.
loss 함수는 학습을 하면서, 실제 데이터와 비교해보고, 여기서 나오는 오차를 계산하여 얼마만큼의 오차가 나오는지를 판별하는 역할입니다.
optimizer는 오차가 나왔을 때, 그것의 최솟값을 찾게 해주는 함수라고 생각하시면 됩니다.
(loss와 optimzer는 각각 다른 포스팅에서 다루겠습니다.)
마지막으로 fit()함수로 어떻게 쪼개서(batch_size), 몇번이나 학습할것인가(epochs)를 설정해주면 완료됩니다.
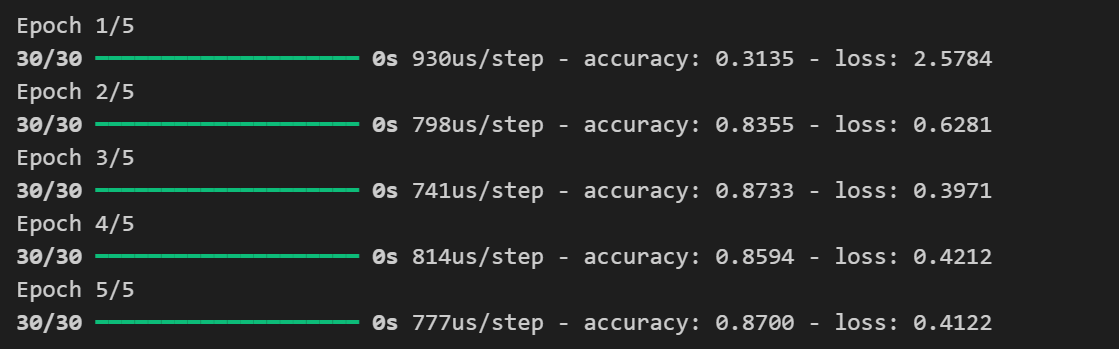
다음은 학습 결과 입니다. 5번 돌렸더니 정확도는 87%, 오차는 0.4 만큼 나온 모델이 탄생한것을 확인할 수 있습니다.
댓글 남기기